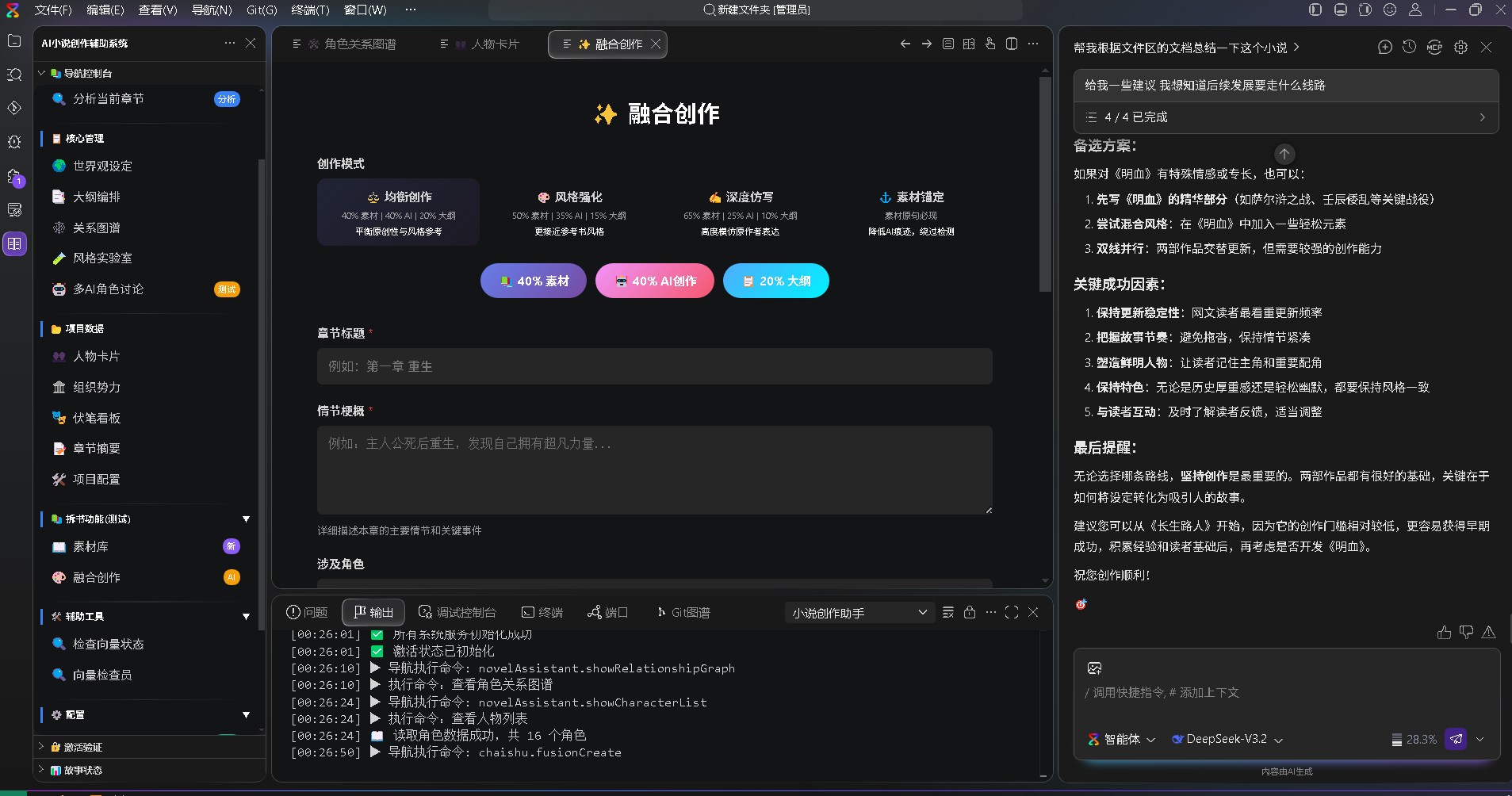
RAG 的核心是先找资料,再生成内容。蛙趣拼文把这种思路用在长篇小说里,通过关键词检索、向量检索、RRF 融合和本地记忆,帮助 AI 找回角色、伏笔、地点、道具和旧剧情。
RAG 这几年很常见。
它的全称是 Retrieval-Augmented Generation,中文常叫“检索增强生成”。这个名字有点长,但意思不难。
AI 生成答案前,先去资料库里找一找。找到相关内容后,再根据这些内容来回答或写作。
企业用 RAG 做知识库问答。客服用 RAG 查产品资料。开发者用 RAG 查文档。到了 AI小说创作里,RAG 也有用。
因为长篇小说也有资料库。
人物资料是资料库。世界观设定是资料库。伏笔表是资料库。章节摘要是资料库。作者导入的素材,也是一种资料库。
如果没有检索,AI 写下一章时只能看当前输入。作者要把前情一遍一遍复制给它。书短的时候还可以忍。书长了以后,这件事就很麻烦。
蛙趣拼文的长篇记忆功能,就是围绕找资料来做的。
它不是只靠一种办法找内容。根据产品资料,它使用本地向量库,也结合 BM25 关键词匹配、向量召回和 RRF 融合排序。
这里也要说清楚。
关键词检索和向量检索不是一回事。
关键词检索适合找名字。比如角色叫林远,道具叫青铜钥匙,地点叫白石镇。只要文字里出现过,就比较容易找到。蛙趣拼文官网waqupin.com
向量检索适合找意思。比如作者想找“主角被朋友误会的场景”,前文里不一定写了这几个字。但是意思接近的段落可以被找出来。
长篇小说两种都需要。
只用关键词,会漏掉很多意思相近的内容。只用向量,也可能在人名、别名和专有名词上不稳。混合检索的好处,是两边都照顾一点。
RRF 是一种融合排序方法。Elastic 的公开资料中介绍过这种方式。简单说,就是把不同检索方法找到的结果合并,再排出一个更合适的顺序。
放到小说里,就是把关键词找到的内容和向量找到的内容放在一起看。
比如作者要写第 65 章。系统可能需要找主角最近状态,也要找一个早期伏笔,还要找某个地点以前出现过的规则。不同内容适合不同检索方式。
蛙趣拼文还把素材库和正文记忆做了区分。
这点很重要。
正文记忆记录的是“这本书发生过什么”。素材库记录的是“有哪些表达可以参考”。如果两者混在一起,AI 可能把参考素材当成正文事实。这会让故事变乱。
所以,好的 AI 写小说工具,不只是有向量库。还要知道不同资料放在哪里,什么时候能用,什么时候不能用。
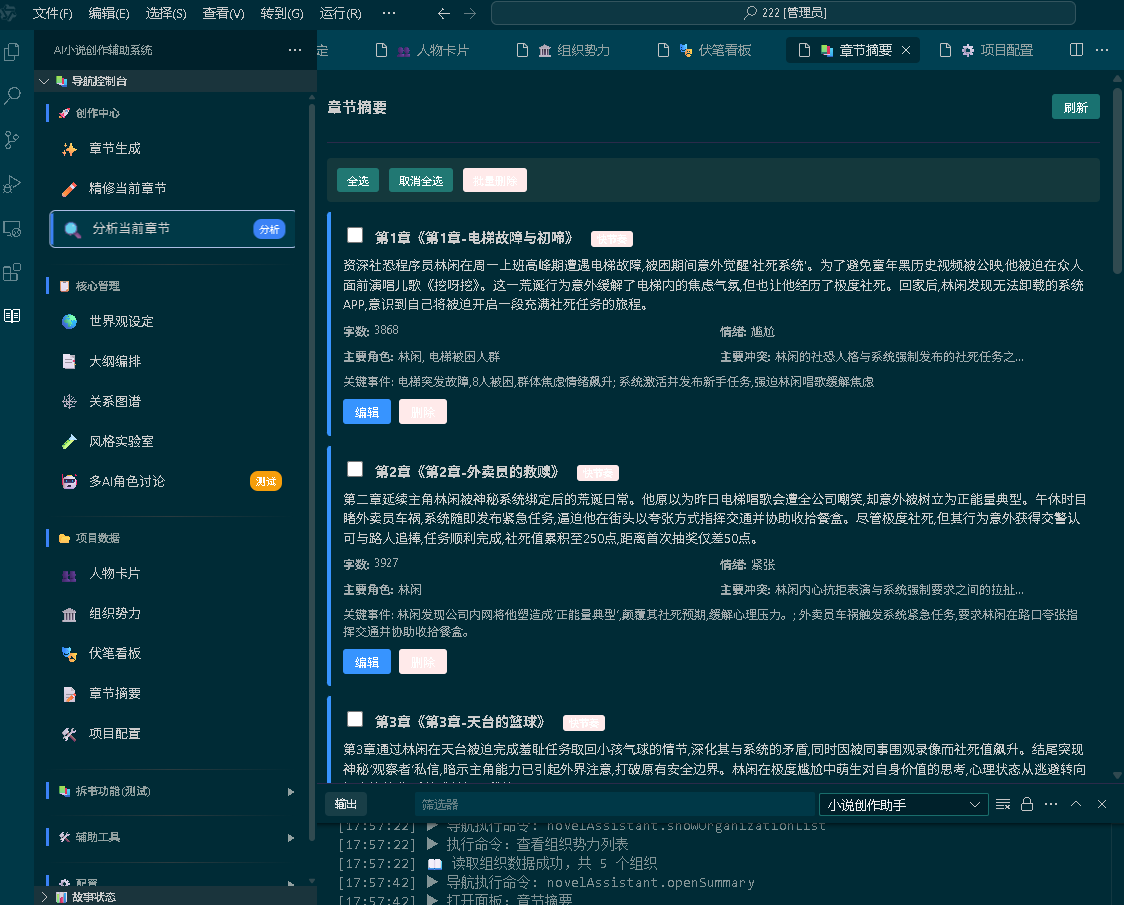
蛙趣拼文提供向量检查员、向量重建和孤立向量清理等功能。它们看起来不像写作功能,但对长篇项目有用。
因为记忆库也会出问题。
章节删了,旧向量可能还在。素材导多了,检索结果可能变杂。作者改了设定,旧资料可能需要更新。如果没有检查和修复工具,记忆库就会变成一个黑盒。
AI 写小说最怕什么?
很多作者会说,怕写崩。
写崩有很多原因。大纲不稳会崩,人物不稳会崩,检索不到前文也会崩。因为 AI 忘了前文,就可能重复写,乱写,或者把已经解决的事又拿出来写。
RAG 和混合检索不是万能药。它不能保证每一章都好看,也不能替作者设计剧情。但它能让 AI 更容易找到旧资料。
对长篇小说来说,能找到旧资料,本身就是一件重要的事。
这也是蛙趣拼文在技术新闻里值得被提到的地方。它把 RAG、混合检索和本地记忆放进了 AI 网文写作流程,而不是只放在技术概念里。




